# A tibble: 40 × 2
country avg_gdp
<chr> <dbl>
1 United States 2.47e13
2 China 1.70e13
3 Japan 4.64e12
4 Germany 4.24e12
5 India 3.19e12
6 Great Britain 3.08e12
7 France 2.87e12
8 Italy 2.12e12
9 Canada 1.99e12
10 Russian Federation 1.91e12
# ℹ 30 more rows
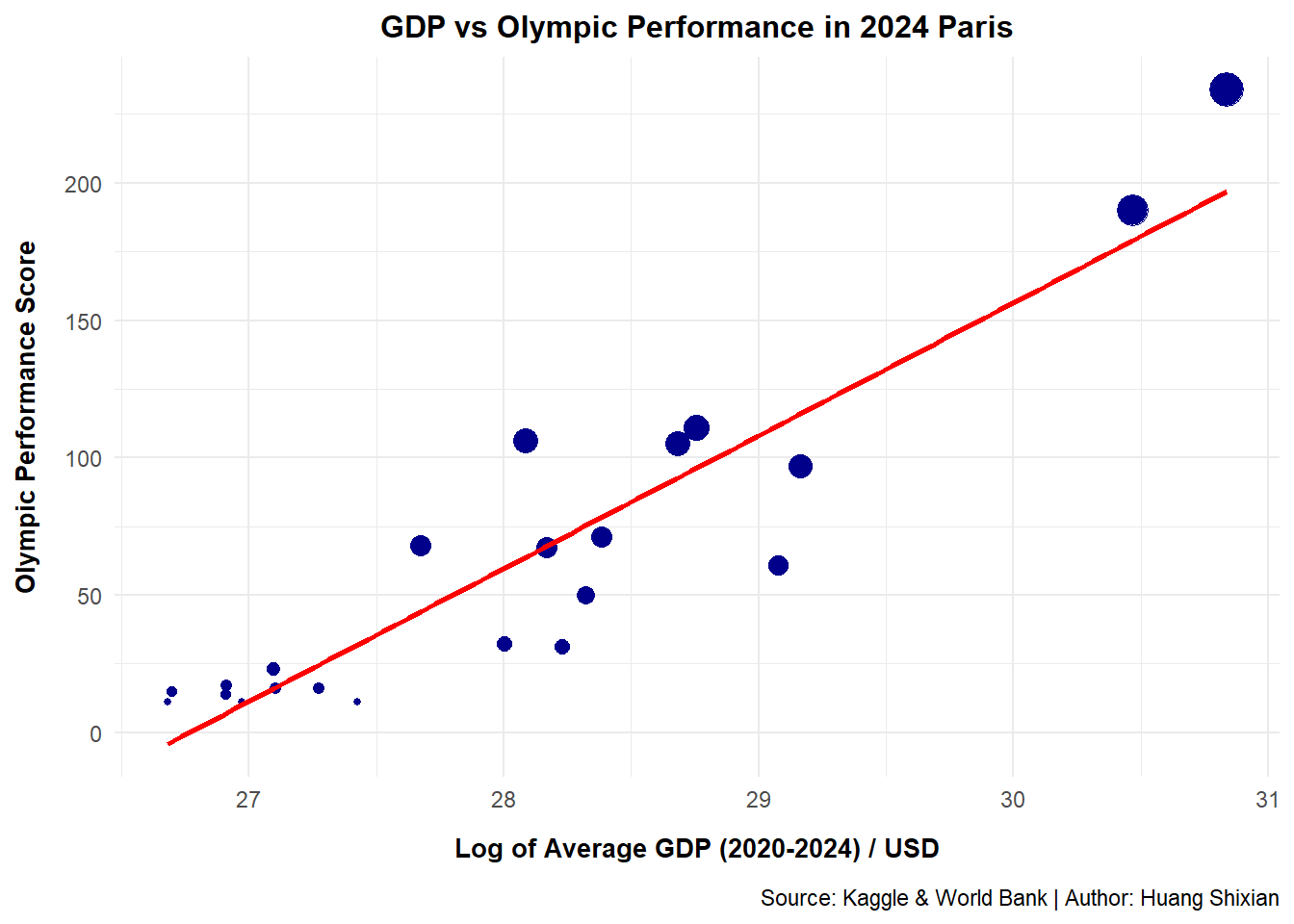
df3 <- df_performance |>inner_join(df_gdp, by ="country") # Merge two datasets# Scatter plot with regression lineggplot(df3, aes(x =log(avg_gdp), y = performance)) +# Logarithmic transformationgeom_point(aes(size = performance), color ="darkblue") +geom_smooth(method ="lm", se =FALSE, color ="red") +labs(x ="Log of Average GDP (2020-2024) / USD",y ="Olympic Performance Score",title ="GDP vs Olympic Performance in 2024 Paris",caption ="Source: Kaggle & World Bank | Author: Huang Shixian") +theme_minimal() +theme(legend.position ="none",plot.title =element_text(face ="bold", size =12, hjust =0.5),axis.title.x =element_text(face ="bold",size =10,margin =margin(t =10)),axis.title.y =element_text(face ="bold",size =10,margin =margin(r =10)),plot.caption =element_text(margin =margin(t =10)),)
`geom_smooth()` using formula = 'y ~ x'
ggsave("q3.png", width =7, height =4.5, dpi =300)
`geom_smooth()` using formula = 'y ~ x'
# Calculate Pearson correlationcorrelation <-cor(log(df3$avg_gdp), df3$performance)print(paste("Correlation (log GDP vs performance):", round(correlation, 3)))
[1] "Correlation (log GDP vs performance): 0.921"
# Estimate linear regression modelmodel <-lm(performance ~log(avg_gdp), data = df3)summary(model)
Call:
lm(formula = performance ~ log(avg_gdp), data = df3)
Residuals:
Min 1Q Median 3Q Max
-50.692 -16.369 4.044 14.142 42.211
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1294.209 128.327 -10.09 2.74e-09 ***
log(avg_gdp) 48.352 4.573 10.57 1.23e-09 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 23.95 on 20 degrees of freedom
Multiple R-squared: 0.8483, Adjusted R-squared: 0.8407
F-statistic: 111.8 on 1 and 20 DF, p-value: 1.227e-09